L’analyse lexicale se trouve tout au début de la chaîne de compilation, elle collabore avec l’analyse grammaticale pour passer de la syntaxe concrète à la syntaxe abstraite. La mission de l’analyse lexicale est de transformer une suite de caractères en une suite de mots, dit aussi lexèmes (tokens). Procéder ainsi en deux temps, en reconnaissant d’abord les mots, puis les phrases, n’est pas justifié par la théorie. En effet, un analyseur grammatical est strictement plus puissant qu’un analyseur lexical et il pourrait reconnaître les mots. La justification est pratique, l’analyseur grammatical est bien plus facile à écrire une fois les mots reconnus.
La production d’un arbre (de syntaxe abstraite) à partir d’une suite de caractères se retrouve comme première passe dans de nombreuses applications (analyses des commandes, des requêtes, etc.).
Les deux analyses (lexicales et syntaxiques) utilisent de façon essentielle les automates, mais on retrouve aussi les automates dans de nombreux domaines de l’informatique. L’analyse lexicale s’explique dans le cadre restreint des automates finis et des expressions régulières (le terme français « autorisé » est expression rationnelle, mais je préfère adapter la terminologie anglaise). Les expressions régulières sont utilisées dans de nombreux outils Unix (éditeur de textes, commande grep etc.), et fournies en bibliothèque dans la plupart des langages de programmation.
Note L’étude détaillée des automates constitue un cours à part entière. Nous nous contentons ici de la présentation formelle minimale, avec comme but :
Le but du cours n’est pas d’écrire le moteur d’un analyseur, ni de répertorier toutes les techniques d’analyse, mais un peu de théorie ne nuit jamais (voir la section 4.6).
On se donne un ensemble Σ appelé alphabet, dont les éléments sont appelés caractères. Un mot (sur Σ) est une séquence de caractères (de Σ). On note є le mot vide, uv la concaténation des mots u et v (la concaténation est associative avec є pour élément neutre). On note Σ ∗ l’ensemble des mots sur Σ.
Un langage sur Σ est un sous-ensemble L de Σ∗. On se donne quelques opérations sur les langages. Si U et V sont des langages sur Σ, on note U V l’ensemble des mots obtenus par la concaténation d’un mot de U et d’un mot de V; U ∗ (resp. U +), l’ensemble des mots obtenus par la concaténation d’un nombre arbitraire, éventuellement nul (resp. non nul) de mots de U.
La description de langages des mots (voir L1 et L3) qui servent à leur tour à définir des langages des phrases (voir L2 et L4) est relativement simple. On précise formellement cette simplicité en disant que ces langages des mots se décrivent à l’aide du formalisme relativement limité des expressions régulières.
On note a, b, etc. des lettres de Σ, M et N des expressions régulières, [[M]] le langage associé à M.
D’autres constructions sont utiles en pratique et exprimables à l’aide des précédentes :
. » (ou underscore _) pour Σ et ∗ pour
Σ∗. La première de ces construction est exprimable comme
l’alternative de tous les caractères de l’alphabet, la seconde comme
la répétition de la première.
Notons un point de vocabulaire. Lorsqu’un mot appartient à un langage défini par une expression régulière, on dit aussi l’expression (ici dénommée motif) filtre le mot.
Les langages réguliers sont ceux qui peuvent se définir à l’aide des expressions régulières. Dans nos exemples, L1 est clairement régulier (alternative de tous les mots du dictionnaire, qui est fini) et nous allons voir comment exprimer L3 avec des expressions régulières. C’est essentiellement l’absence de la récursion qui limite les langages réguliers, ainsi on peut montrer que le langage L5 (les parenthèses) n’est pas régulier.
Le shell Unix utilise les expressions régulières pour spécifier les noms de fichiers. La commande suivante donne la liste de tous les sources Caml dans le répertoire courant :
# ls *.ml{,[ily]}
Notez bien qu’ici l’alternative est exprimée avec la virgule
« , », le mot vide par rien, et que les accolades sont un
simple parenthésage.
Dès lors, la commande précédente donne la liste des fichiers dont
l’extension est .ml, .mli, .mll (sources du
générateur d’analyseurs lexicaux ocamllex), et .mly
(sources du générateur d’analyseurs syntaxiques ocamlyacc).
Les lexèmes sont définis par l’alternative d’expressions régulières. Par exemple :
"let", "in".
En général, les mots-clés ne peuvent pas être utilisés comme noms de
variables. Ce parti pris évite pas mal d’ambiguïtés lors de l’analyse
grammaticale ultérieure.
['A'-'Z' 'a'-'z'] ['A'-'Z' 'a'-'z' '0'-'9']*.
Les noms des variables sont des suites de lettres et de chiffres
commençant obligatoirement par une lettre.
['0'-'9']+
'(', ')', '+', '*', '-',
'/','='.
[' ' '\n' '\t']. Les caractères
'\n' et '\t' sont respectivement le retour à la ligne et
la tabulation.
On est passé ici en notation Caml, où un caractère est donné entre
quotes (et une suite de caractères entre double quotes), si on veut
le caractère quote « ' », il vaut mieux écrire
'\''.
Une fois les lexèmes reconnus, ils sont représentés par un type somme dont nous noterons au passage qu’il n’est pas récursif :
| type token = | LET | IN (* mots-clés *) | VAR of string (* variables *) | INT of int (* entiers *) | LPAR | RPAR | ADD | SUB | MUL | DIV | EQUAL (* symboles *) |
On notera aussi que les blancs sont omis, c’est à dire qu’ils sont peut être des mots du langage mais sont oubliés en route. De fait les blancs servent surtout à séparer les lexèmes.
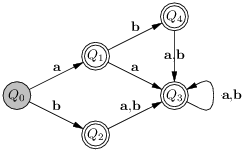
Il est bien connu que les automates finis (j’en dis un peu plus par la suite) savent reconnaître les langages réguliers, c’est à dire qu’étant donné un langage régulier L on peut construire un automate qui, lorsque l’on lui présente un mot sait répondre par oui ou par non à la question de l’appartenance du mot à L. Très rapidement, l’automate est un graphe dont les sommets sont des états et les arcs des transitions, l’automate est à un instant donné dans un état donné et la consommation d’une lettre du mot le fait changer d’état en suivant une transition. Lorsque le mot est entièrement consommé le mot est reconnu si l’état courant est un état particulier dit final. Par exemple, voici deux automates finis qui reconnaissent respectivement le mot-clé let et les entiers (suite non vide de chiffres). Dans ces dessins, les état initiaux sont grisés et les états finaux encerclés.

Dans le second automate, chaque transition en remplace dix, si on suit le formalisme strict des automates. Ensuite, pour reconnaître le mot clé let ou un entier, on peut regrouper les deux automates précédents :
On a, ici dans un cas simple, construit l’automate qui reconnaît l’alternative de deux expressions régulières. Selon l’état final atteint (4 ou 5) on connaîtra le lexème reconnu.
Toutefois, ceci ne suffit pas tout à fait pour expliquer l’analyse lexicale, nous savons peut être reconnaître si un mot est dans L, mais nous devons, d’une part, reconnaître une suite de mots de L, et d’autre part, savoir de quels mots il s’agit. Intuitivement, un automate peut facilement reconnaître que le mot présenté est bien une suite de mots de L. En effet, le langage d’une suite de mots de L se définit à l’aide de l’opérateur de répétition ∗. Mais on ne sait pas alors quels mots ont été reconnus, il vaut mieux reconnaître les mots un par un. Conceptuellement, il suffit d’arrêter l’automate dans un état final sans attendre la fin du mot, puis de recommencer sur la partie non consommée du mot présenté.
Mais il y a encore des cas douteux :
let pourrait être reconnu comme une variable.
lettre pourrait aussi être reconnu comme la séquence
LET; VAR "tre" ou encore comme la séquence
VAR "let"; VAR "tre".
Ces ambiguïtés se lèvent à l’aide de règles spécifiques. Lors de la reconnaissance d’un mot de L, on cherchera :
Ainsi la phrase let lettre = 3 in 1 + fin devrait produire
la suite de lexèmes :
En raison de la règle du lexème le plus long et à condition que, à taille égale, la reconnaissance des mots-clés prime celle des variables.
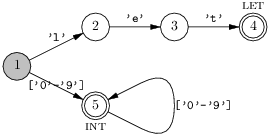
La règle de priorité numéro deux (sur l’ordre de présentation) se réalise simplement au moment de la fabrication de l’automate. Voici par exemple un automate qui reconnaît le mot-clé let ainsi que les identificateurs composés simplement de lettres minuscules, le mot-clé étant prioritaire.
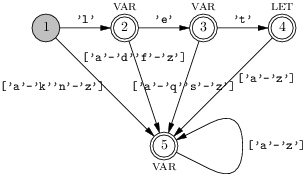
L’état final 4 pourrait bien correspondre à une variable ou à let, on choisit de le faire correspondre à la reconnaissance du mot-clé.
Sur cet exemple on peut aussi appréhender la réalisation de la règle du lexème le plus long. Tout en consommant les caractères de l’entrée, on peut se souvenir du dernier état final rencontré. Ensuite, lorsque l’automate est bloqué, ici par exemple si il y a un chiffre dans l’entrée, alors on peut revenir au dernier état final vu. Le blocage est facilement détecté en ajoutant un état dit bloqué à l’automate et en complétant les transitions issues de tous les états par des transitions vers l’état bloqué.
Nous ne savons pas précisément comment, à partir de la définition des lexèmes donnés comme expressions régulières, fabriquer l’automate qui les reconnaît. Nous admettons que cet automate existe. Bien mieux, il existe un programme ocamllex qui sait le construire pour nous.
L’outil ocamllex est lui même un compilateur, qui prend comme source les expressions régulières (dans un fichier nom.mll) et produit un programme Ocaml (dans un fichier nom.ml), programme qui réalise l’automate.
{ open Token exception Error } rule token = parse (* Les lexèmes stricto-sensu *) | '(' {LPAR} | ')' {RPAR} | '+' {ADD} | '-' {SUB} | '*' {MUL} | '/' {DIV} | '=' {EQUAL} | "let" {LET} | "in" {IN} | ['A'-'Z' 'a'-'z'] ['A'-'Z' 'a'-'z' '0'-'9']* {VAR (Lexing.lexeme lexbuf)} | ['0'-'9']+ {INT (int_of_string (Lexing.lexeme lexbuf))} (* Règles supplémentaires *) | eof {EOF} | [' ''\n''\t' ] {token lexbuf} | "" {raise Error}
Commençons par un exemple, celui d’un analyseur lexical pour calculette avec let. On écrit le source de la figure 4.1 dans un fichier lexer.mll, la commande :
# ocamllex lexer.mll
produit un nouveau fichier lexer.ml. L’exemple suffit déjà pour expliquer pas mal de choses sur la structure des fichiers source de ocamllex.
rule et parse. Chaque règle est constituée d’une
expression régulière (le motif) et d’une action, du code Caml à
exécuter après reconnaissance.
Les premières règles de la parenthèse ouvrante au mot-clé (de la
calculette) in ne posent pas de problème, l’action est de
rendre le lexème reconnu.Notons qu’à partir de la version 3.07 de Caml, on peut écrire.
| | ['A'-'Z' 'a'-'z'] ['A'-'Z' 'a'-'z' '0'-'9']* as lxm {VAR lxm} | ['0'-'9']+ as lxm {INT (int_of_string lxm)} |
C’est à dire qu’il est possible de lier la chaîne reconnue à une
variable quelconque (ici lxm) à
l’aide de la construction as.
eof.
Cela indique la fin du flux d’entrée, l’automate rend alors un lexème
spécifique qui aurait dû être ajouté à la définition des lexèmes de la
section 4.3.1.
Après la compilation de lexer.mll, le fichier
lexer.ml contient donc la réalisation de l’automate
token sous la forme d’une fonction de type
Lexing.lexbuf -> Token.token.
La « mission » de cette fonction est de reconnaître et renvoyer le
lexème présent au début de son entrée et de consommer les caractères
correspondants. La consommation des caractères n’est pas explicitée par
le type, elle s’opère par effet de bord sur le flux passé en argument.
À titre d’exemple, voici un petit bout de code Caml qui
compte les lexèmes présents dans l’entrée standard.
| let entrée = Lexing.from_channel stdin in (* Fabriquer le flux *) let count = ref 0 in while Lexer.token entrée <> Token.EOF do count := !count + 1 done ; Printf.printf "J'ai lu %d lexèmes\n" !count |
Mon propos n’est pas donner une description exhaustive de ocamllex. Ceux qui sont intéressés peuvent commencer par consulter le manuel. Je vais plutôt décrire quelques exemples et en profiter pour introduire d’autres traits de ocamllex.
Commençons donc par considérer le cas des commentaires. Il est naturel de supprimer les commentaires dès l’analyse lexicale, ainsi les commentaires n’ont aucun impact sur toutes les phases suivantes du compilateur. Il y a trois sortes de commentaires.
| // Je suis un commentaire. |
| | "//" [^'\n']* '\n'? {token lexbuf} |
[^'\n']* (une suite de caractères différents du retour à la
ligne) et non pas _* (n’importe quel mot).
En effet, avec le second motif, les commentaires s’étendraient du
premier // au dernier retour à la ligne, en raison de la règle
du lexème le plus long.
On notera encore que le retour à la ligne est optionnel '\n'?, afin
de considérer aussi un commentaire en fin d’entrée et sans retour à
la ligne.| /* Je suis un commentaire, sur deux lignes. */ |
| rule token = parse ... | "/*" {incomment lexbuf} and incomment = parse | "*/" {token lexbuf} | _ {incomment lexbuf} | eof {raise Error} |
À la reflexion, l’expression régulière suivante fonctionne aussi :
| rule token = parse ... | "/*" ([^'*']|('*'+[^'*''/']))* '*'+ '/' {token lexbuf} |
L’expression régulière ([^'*']|('*'+[^'*''/']))* décrit
touts les mots qui ne contiennent pas "*/",
sauf les suites non vides de '*',
tandis que '*'+ '/' décrit les suites (possiblement vides) de
'*' suivies de "*/".
On peut trouver le premier motif en cherchant à expliciter le complément
de "*/".
Vous trouverez à la fin de la leçon une autre
méthode pour trouver cette expression régulière.
| (* Un commentaire (* avec un commentaire dedans *) *) |
| { let depth = ref 0 } rule token = parse ... | "(*" {depth := 1 ; incomment lexbuf} and incomment = parse | "*)" {depth := !depth-1 ; if !depth <= 0 then (* où en sommes nous ? *) token lexbuf (* on ferme le premier "(*" *) else (* on ferme un autre "(*" *) incomment lexbuf} | "(*" {depth := !depth+1 ; incomment lexbuf} | _ {incomment lexbuf} | eof {raise Error} |
Il est possible de se passer du compteur global réalisé à l’aide de la
référence depth et de le remplacer par un
argument supplémentaire donné à la règle
incomment.
| rule token = parse ... | "(*" {incomment 1 lexbuf} and incomment depth = parse | "*)" {if depth <= 1 then (* où en sommes nous ? *) token lexbuf (* on ferme le premier "(*" *) else (* on ferme un autre "(*" *) incomment (depth-1) lexbuf} | "(*" {incomment (depth+1) lexbuf} | _ {incomment lexbuf} | eof {raise Error} |
On notera enfin que les commentaires du source ci-dessus ne seraient pas
correctement éliminés, en raison de la présence de la chaîne
"(*" dans les commentaires.
Il faudrait pour dépasser ce petit inconvénient, ignorer le contenu des
chaînes dans les commentaires à l’aide d’un troisième automate.
Considérons maintenant les chaînes (du langage analysé)
définies comme tout ce qui se
trouve entre deux caractères double quote « " ».
On ajoute donc un lexème
STRING of string au type des lexèmes et
on cherche comment reconnaître les chaînes de l’entrée.
Si le double quote est interdit dans les chaînes, alors il n’y a pas de difficulté on s’en tire un peu comme dans le cas des variables.
| | '"' [^'"']* '"' as lxm (* Noter: '"' est le caractère « " » *) {(* supprimer le premier et le dernier caractère de lxm *) STRING (String.sub lxm 1 (String.length lxm-2))} |
On peut éviter l’appel aux fonctions du module
String, car la construction
as permet aussi de nommer des
sous-chaînes de la chaîne reconnue par le motif. On écrira donc:
| | '"' ([^'"']* as content) '"' {STRING content} |
Mais le programmeur peut légitimement vouloir mettre un double quote
dans une chaîne.
Le concepteur prévoit alors un mécanisme de citation (quotation) :
à l’intérieur d’une chaîne \" veut dire « " » et
\\ veut dire « \ » (pour donner un moyen de mettre
« \ » à la fin d’une chaîne).
Je me félicite des guillemets français qui signifient ce caractère là.
Comme il n’y a pas de notion de chaînes imbriquées dans les chaînes, on
a le net sentiment que l’on va pouvoir s’en sortir à l’aide
d’un automate supplémentaire instring, comme pour les commentaires
/*… */.
Il y a une petite différence, ici on doit renvoyer en résultat les
caractères de la
chaîne reconnue et non plus les ignorer.
Pour éviter les recopies de chaîne en pagaille,
ou pourrait employer des listes de caractères.
Nous allons plutôt employer un
tampon (buffer) tel que défini par le module
Buffer de la bibliothèque standard
(c’est en gros le même fonctionnement que la classe
StringBuffer de Java).
{ let sbuff = Buffer.create 16 (* fabriquer le buffer *) } rule token = parse ... | '"' {STRING (instring lexbuf)} and instring = parse (* Fin de la chaîne *) | '"' {let r = Buffer.contents sbuff in (* récupérer le contenu de sbuff *) Buffer.clear sbuff ; (* réinitialiser sbuff *) r} (* Caractères cités *) | '\\' ('"'|'\\' as c) (* c est le second caractère reconnu *) {Buffer.add_char sbuff c ; (* à mettre à la fin de sbuff *) instring lexbuf} | _ as c {Buffer.add_char sbuff c ; instring lexbuf} | eof {raise Error}
On notera d’abord, dans le code de la figure 4.2,
l’utilisation de la la construction as
pour récupérer un caractère de l’entrée.
Ce qu’il faut remarquer c’est que, dans la construction
motif as variable, variable est de type
char quand motif est un motif
caractères ou une alternative de motifs caractère. Jusqu’ici,
motif pouvait filter des chaînes de longueur diverses et le
type de variable était string.
On remarquera aussi que le type de l’automate instring est
Lexing.lexbuf -> string.
Enfin, on ne se laissera pas intimider par les mécanismes de
citation de Caml : la notation
'\\' désigne bien le caractère « \ ».
Dans un langage programmation normal il y a souvent un nombre important de mots-clés. En principe cela ne pose pas de problème, il suffit de se donner une règle de reconnaissance par mot-clé et ocamllex construit l’automate. Mais en pratique, si il y beaucoup de mots-clés, l’automate sera gros voire énorme. On peut surmonter cet inconvénient en utilisant la clé anglaise de la programmation : la table de hachage. (La clé anglaise taiwanaise est un outil bon marché et polyvalent, mais moins efficace qu’une clé plate Facom de la bonne taille.) Les tables de hachage sont disponibles en Caml dans le module Hashtbl de la bibliothèque standard. Les tables de hachage définissent des associations de n’importe quoi à n’importe quoi, on les utilise ici pour définir une association des chaînes aux lexèmes. Une fois une suite de lettres reconnue, on vérifie si par hasard cette suite de lettres n’est pas un mot-clé. Si oui, on a reconnu le mot-clé, si non, on a reconnu un identificateur (voir la figure 4.3).
{ let keywords = Hashtbl.create 17 (* création de la table de hachage *) (* initialisation de la table *) let _ = Hashtbl.add keywords "let" LET ; (* associer LET à "let" *) Hashtbl.add keywords "in" IN ; (* associer IN à "in" *) ... } rule token = parse ... | ['a'-'z']+ {let lxm = Lexing.lexeme lexbuf in try Hashtbl.find keywords lxm (* chercher lxm dans la table *) with Not_found -> (* lxm n'est pas un mot-clé *) Var lxm } (* c'est donc un identificateur *)
On remarquera l’utilisation plutôt simple des tables de hachage et le respect de la sémantique des mots-clés prioritaires sur les identificateurs.
Pour le moment nos analyseurs se contentent signaler les erreurs, sans
donner aucune information spécifique.
On peut enrichir l’information donnée au programmeur en différenciant
les erreurs, pour signaler un caractère illégal, une chaîne
non-terminée etc.
Mais l’information qui aidera sans doute le plus le programmeur est
une position dans le fichier analysé.
Or, dans une action, la fonction Lexing.lexeme_start
(resp. Lexing.lexeme_end) fournit
la position dans l’entrée du début (resp. de la fin) du dernier
lexème reconnu.
On peut alors transmettre cette position comme argument de l’exception
Error en l’accompagnant d’un message
d’erreur explicatif.
| { exception Error of int * string let error pos = raise (Error (pos,msg)) } rule token = parse ... | "" {error (Lexing.lexeme_start lexbuf) "Caractère illégal"} and incomment = parse ... | eof {error (Lexing.lexeme_start lexbuf) "commentaire non terminé"} |
En fait, il faudrait travailler un petit peu plus pour par exemple transmettre la position du commentaire ouvert et non refermé.
Dans le cas où l’entrée est un fichier, la position comptée en caractères à partir du début du fichier est assez peu pratique, même si un éditeur tel que emacs sait automatiquement retrouver une telle position. Il est plus pratique de donner la position sous la forme d’un numéro de ligne et d’un compte de caractères à partir du début de la ligne. Considérons par exemple le fichier er.ml suivant :
let x = 1 let y = "coucou let z = 1
La tentative de compilation ocamlc er.ml donne :
File "er.ml", line 2, characters 8-9: String literal not terminated
Le compilateur retrouve assez facilement un numéro de ligne à partir d’une position (en réouvrant le fichier), et le confort d’utilisation gagné vaut ce petit effort.
Une autre possibilité est de tenter de corriger les erreurs (en les signalant tout de même !) et de reprendre l’analyse. On pourra par exemple simplement ignorer les caractères spéciaux. Mais c’est en fait difficile et souvent un peu vain, car l’analyseur aura du mal à deviner ce que le programmeur a en tête. Il ne saura pas, par example, où refermer une chaîne qui court jusqu’à la fin de l’entrée.
Un outil tel que ocamllex facilite l’écriture des analyseurs lexicaux, mais il n’est pas très pratique pour programmer à l’aide des expressions régulières, comme on le fait par exemple beaucoup en Perl. En effet, on doit mettre l’analyseur dans son propre fichier .mll ce qui est un peu lourd. Par ailleurs, les générateurs d’analyseurs lexicaux visent plutôt un public de concepteurs de compilateurs et leurs concepteurs ne proposent pas toujours quelques traits courants et pratiques qui séduisent le plus vaste public des programmeurs. Des bibliothèques « d’expressions régulières » répondent à ce besoin de plus grande flexibilité et d’expressivité étendue.
En Caml, on dispose de la bibliothèque Str. Elle ne sera pas décrite ici, ceux qui sont intéressés peuvent consulter le manuel. Il y a deux points notables :
('a'|'b'),
en Str on écrira \(a\|b\).
Enfin, ce n’est pas tout à fait exact, les caractères $^.*+?[] sont spéciaux et doivent parfois être cités avec « \ » pour se
signifier eux mêmes.
Nous nous contenterons donc d’un exemple simple.
Nous cherchons à reconnaître des adresses de courrier électroniques
de la forme
Prénom.Nom@polytechnique.fr, afin
d’en extraire le nom.
En outre, nous acceptons les variations de casse dans le nom de domaine
polytechnique.fr.
Le code est donné par la figure 4.4.
open Str open Printf (* - ^ initial -> début de ligne - [^.] -> tout sauf le point - \. -> un point - \(... \) -> groupage, groupes numérotés de gauche à droite - .* -> n'importe quelle chaîne - $ -> fin de ligne *) let auto = regexp "^[^.]+\.\([^@.]+\)@\(.*\)$" (* compilation de l'automate *) let extrait s = if string_match auto s 0 && (* filtrage *) String.lowercase (matched_group 2 s) = (* extraction 2ème groupe *) "polytechnique.fr" then printf "Le nom est %s\n" (matched_group 1 s) (* extraction 1er groupe *) else printf "Ce n'est pas une adresse de l'X\n"
La bibliothèque Str ne fait pas partie de la bibliothèque standard. Par conséquent, l’argument str.cma doit être donné explicitement lors de l’édiction de liens:
# ocamlc options str.cma files…
Cette section culturelle explique les principes des générateurs d’analyseurs lexicaux tels que ocamllex. Le principe général est celui d’une véritable compilation des expressions régulières aux automates.
Un automate fini déterministe M est un quintuplet (Σ, Q, δ, q0, F) où
On peut étendre δ sur Q × Σ ∗→ Q par
| ⎧ ⎨ ⎩ |
|
Le langage L(M) reconnu par l’automate M est l’ensemble { w ∣ δ (q0, w) ∈ F } des mots permettant d’atteindre un état final à partir de l’état initial.
Exemple Soit un automate :
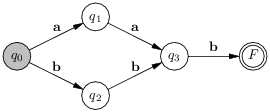
L’automate reconnaît le langage {aab, bbb}, La formalisation comme un quintuplet est laissée en exercice.
La définition est la même que celle de automates déterministes, compte tenu des deux détails suivants :
On peut exprimer ces modifications en définissant les transitions entre états comme une relation δ (fonction dans les booléens) sur Q × (Σ ∪ {є}) × Q. Une telle relation peut aussi très bien se noter comme une liste de triplets q ↦a q′.
On étend δ sur Q × Σ ∗× Q par
| ⎧ ⎪ ⎨ ⎪ ⎩ |
|
(Il y a un peu d’abus, la relation définie est le point fixe des implications et il y a quelques quantificateurs implicites.)
Le langage L(M) reconnu par un automate non déterministe est {w ∣ ∃ qf ∈ F, δ (q0, w, qf)} . Notons, et c’est assez intéressant, que les transitions définissent aussi une fonction de Q × Σ ∗ vers 2Q (ensembles d’états) : à un état q et un mot w, on associe l’ensemble Q′ des états q′ tels que la relation δ(q, w, q′) tient.
Exemple Soit un automate :

L’automate reconnaît le langage des mots d’au moins une lettre formés avec a et b. On note que le mot ab peut être reconnu de deux façons différentes (à q0 et ab, on associe {q0, F1, F2}). On peut intuitivement voir la reconnaissance d’un mot par un tel automate comme le calcul d’un ensemble d’états effectués ainsi.
Ainsi la consommation du mot ab peut se décrire par les trois dessins suivants (cette fois ci, c’est l’ensemble des états courants qui est grisé).
Nous sommes maintenant équipés pour décrire la fabrication d’un automate fini déterministe reconnaissant un langage régulier donné. Il s’agit d’une véritable compilation qui comprend trois phases successives1.
L’intérêt des automates non-détermistes est qu’il est facile d’associer un automate (Q, δ, s, F) reconnaissant un langage L à une expression régulière M définissant le langage L.
Ce n’est pas la seule construction possible. Par exemple, on peut exprimer graphiquement une construction légèrement différente (la modification ne porte que sur l’alternative). La nouvelle construction produit des automates à un seul état initial et un seul état final. Ces automates sont représentés par des boîtes portant le nom du motif représenté, leur état initial est à gauche et leur état final à droite.

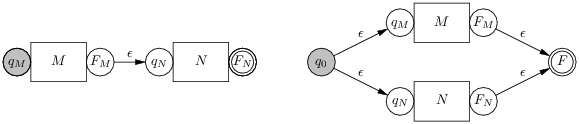

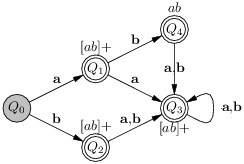
La première construction de l’alternative à l’avantage de laisser intacts les états finaux, de sorte qu’ils dénonceront plus tard la branche choisie. Ainsi, en suivant la première construction de l’alternative et en optimasant le motif [ab], l’expression régulière ([ab]+ ∣ ab) se compile en l’automate suivant :

On peut très bien exécuter directement un automate non-déterministe, en considérant un ensemble d’états courants. Mais la manipulation des ensembles coûte toujours un peu cher, et dans un contexte de compilation, il vaut mieux transformer les NFA en des DFA équivalents (ie. qui reconnaissent le même langage). Cela revient à payer le prix de la réalisation des ensembles une seule fois, et est particulièrement rentable lorsque l’analyseur a vocation a être exécuté de nombreuses fois.
L’idée est inspirée de l’exécution des automates non-deterministes, il suffit de considérer tous les ensembles d’états possibles durant toutes les exécutions possibles. Soit, à partir d’un NFA An = (Q, δ, q0, F) on souhaite trouver un DFA équivalent Ad = (R, γ, Q0, G). On choisira les états de Ad parmi l’ensemble des parties de Q, on notera donc les états de Ad, Q0, Q1, etc. On définit deux fonctions sur 2Q.
L’algorithme de traduction consiste à tout simplement calculer l’ensemble des ensembles d’états atteignables (les Qi) à partir de l’état initial de An, en se rappelant au passage des transitions entre les Qi. Plus formellement, on calcule le point fixe
| R = F({q0}) ⋃ {Qi ∣ ∃ Qj ∈ R ∧ ∃ a ∈ Σ , Qi = F(Ca(Qj))} ⋃ R |
Avec en outre, γ(Qj, a) défini comme Qi = F(Ca(Qj)), et G composé des états de R qui contiennent au moins un état final de F.
Ça à l’air un peu compliqué, mais un exemple expliquera mieux ce qui se passe. Considérons toujours le même automate, celui qui résulte de la compilation de ([ab]+ ∣ ab), en se plaçant dans l’alphabet Σ = {a, b}. Dans un premier temps, nous disposons de l’état initial Q0 = F({q0}) = {q0, q1, q4} les états et les transitions sont ensuite calculées ainsi :
Le calcul est maintenant terminé, car le cas de la consommation de a et b a été examiné à partir de tous les états possibles de Ad et on obtient donc l’automate de la figure 4.5.
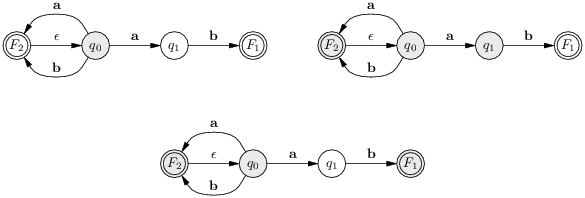
Il est maintenant intéressant d’examiner l’état Q4 qui contient les deux états finaux du NFA F1 et F2. Cet état n’est atteint que si l’entrée est ab. Or, F1 traduit le filtrage de cette entrée par le motif ab, tandis que F2 traduit le filtrage par [ab]+. Ce n’est pas bien grave si on ne s’intéresse qu’à la définition du langage reconnu. En revanche, si l’automate est censé reconnaître un mot-clé (ab) et des variables ([ab]+), il faut faire un choix. Le choix est arbitraire et repose sur l’ordre de présentation des motifs. On suppose pour la suite que ab prime sur [ab]+ et on décore les états finaux par le motif choisi. On obtient l’automate de la figure 4.6.
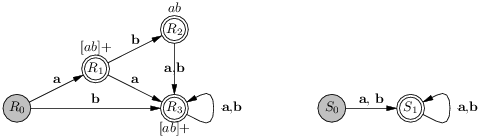
L’automate déterministe donné comme compilation de ([ab]+|ab) n’est pas optimal : il existe un automate plus petit qui reconnaît le même langage que lui. De fait, selon que l’on souhaite distinguer les motifs reconnus ou pas et en revenant à l’expression régulière on trouve facilement deux automates équivalents (voir la figure 4.7).
Évidemment on peut maintenant se demander comment produire un automate optimal à partir d’un automate donné. Je vais juste donner l’idée. Deux états Qi et Qj de l’automate donné sont équivalents, noté Qi ≅ Qj, quand les suffixes du langage L reconnus à partir de ces états sont exactement les mêmes. On peut fusionner les états équivalents, le langage reconnu ne changera pas. Tous les états finaux de l’automate de la figure 4.5 sont équivalents. En effet toutes les reconnaissances amorcées à partir de ces états définissent le langage [ab]*, on peut alors à fortiori fusionner Q1, Q2, Q3 et Q4 en S1. Notons que si l’on distingue les états finaux (figure 4.6), alors on ne peut fusionner que Q2 et Q3.
Le principe d’un algorithme de minimisation est de remplacer les états par les classes d’équivalence de ≅. Un algorithme possible fonctionne par raffinements successifs d’une partition initiale des états en états finaux et non finaux (si les états finaux sont distingués, il y a un élément de la partition initiale par sorte d’état final), jusqu’à obtenir une partition stable sous la relation δ(_,a) pour tous les caractères a. Plus précisément la relation recherchée est :
| ∀ R ∈ P, ∀ Q,Q′ ∈ R × R, ∀ a ∈ Σ, ∃! R′, δ (Q,a) ∈ R′ ∧ δ (Q′,a) ∈ R′ |
Il y a de nombreuses variations de cette idée, les variations concernent surtout l’arrangement des itérations et les structures de données. L’algorithme le plus efficace utilise la relation inverse δ−1.
On peut réaliser les automates directement par du code. En Caml on aura recours à une fonction par état, chaque fonction filtrant le caractère courant. Ainsi, l’automate optimal de gauche de la figure 4.7, donnerait lieu à ce genre de code :
| let rec state0 = function | 'a' -> state1 (next_char ()) | 'b' -> state3 (next_char ()) | _ -> error () and state1 = function | 'a' -> state3 (next_char ()) | 'b' -> state2 (next_char ()) | _ -> "[ab]+" ... |
Mais le code risque d’être assez abondant. On a plutôt tendance à définir l’automate par la table de ses transitions, c’est à dire comme une matrice d’entiers, les lignes étant les états et les colonnes les caractères. Ainsi sur l’alphabet {a, b, c} on a la matrice de transitions :
|
|
Une entrée −1 indique une erreur et le vecteur de droite désigne les états finaux. On peut alors interpréter la table pour réaliser l’automate spécifié. Le calcul d’une transition prend un coût constant, car il consiste à accéder dans un tableau. A priori nous n’avons pas gagné beaucoup de place (car il y a normalement de l’ordre de 256 caractères possibles), mais les matrices de transition sont souvent creuses (chaque ligne possède beaucoup de valeurs identiques). On peut alors représenter la matrice de transition de façon compacte en pratique, tout en gardant un coût constant pour la réalisation d’une transition.
Rappelons que le problème est de trouver une
expression régulière qui
décrit les commentaires de C : il s’étendent d’un mot
"/*" au premier mot "*/" qui suit.
Or, on peut assez facilement trouver
l’automate déterministe qui, laché dans un commentaire, sait
en trouver la fin :
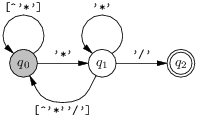
Ensuite on cherche à trouver une expression régulière décrivant le langage de cet automate. On va donc inverser la construction présentée précédemment dans un cas particulier. On duplique d’abord l’état q1 en répartissant astucieusement ses transitions. On a alors l’automate non-déterministe équivalent suivant :

Soit encore, en dupliquant q0 cette fois :
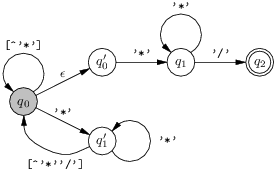
Nous retrouvons maintenant la composition en séquence des deux automates suivants :

Le langage de l’automate de gauche est
([^'*']|('*''*'*[^'*''/'])*
(répétition des deux sortes de chemins possibles de q0 à lui même)
tandis que le langage de l’automate de droite est '*'+ '/' (facile).
Bon, la dérivation de l’expression régulière à partir de l’automate
déterministe manque de généralité, mais elle est correcte.
L’idée étant de vérifier à chaque étape que les chemins de l’état
initial à l’état final ne changent pas.