J usqu'à présent, nous n'avons considéré que l'écriture de
petits programmes ou de fonctions suffisants pour décrire des
structures de données et les algorithmes correspondants. Cependant, la
partie la plus importante de l'écriture de vrais programmes consiste à
définir les structures nécessaires pour présenter les programmes comme
un assemblage de briques s'emboîtant naturellement. Ce problème, qui
peut apparaître comme purement esthétique, se révèle fondamental dès
que la taille des programmes devient conséquente. En effet, si on ne
prend pas garde au bon découpage des programmes en modules
indépendants, on se retrouve rapidement débordé par un grand nombre de
variables et de fonctions, et il devient difficile de
réaliser un programme correct.
Dans ce chapitre, nous considérerons également le style de
programmation par objets, souvent confondu, à tort, avec la
programmation modulaire. Ce style de programmation très populaire
depuis l'apparition des langages Simula et Smalltalk est un principe
de programmation incrémentale, dirigée par l'organisation des données;
ce genre de programmation est plutôt utilisé pour la définition de
bibliothèques graphiques, comme AWT en Java, ou de bibliothèques de
fonctions appelées à distance à travers un réseau.
Dans ce chapitre, il sera question de modules, d'interfaces, de
compilation séparée, de reconstruction incrémentale de programmes,
et de programmation par objets.
| 3.1 |
Un exemple: les files de caractères |
|
Pour illustrer notre chapitre, nous considérons diverses
implémentations des files de caractères. Ce type de données est
utilisé, par exemple, pour gérer les entrées/sorties d'un terminal
(tty driver) ou du réseau Ethernet. Commençons par des
implémentations classiques avec un tampon circulaire et avec des
listes chaînées.
public class FC {
private int debut, fin;
private boolean vide, pleine;
private char[ ] contenu;
public FC (int n) {
debut = fin = 0; vide = true; pleine = n == 0;
contenu = new char[n];
}
public static void ajouter (char x, FC f) {
if (f.pleine)
throw new Error ("File Pleine.");
f.contenu[f.fin] = x;
f.fin = (f.fin + 1) % f.contenu.length;
f.vide = false; f.pleine = f.fin == f.debut;
}
public static char supprimer (FC f) {
if (f.vide)
throw new Error ("File Vide.");
char res = f.contenu[f.debut];
f.debut = (f.debut + 1) % f.contenu.length;
f.vide = f.fin == f.debut; f.pleine = false;
return res;
} |
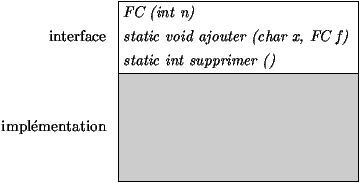
Figure 3.1 : Interface d'un module
Les champs debut, fin, pleine, vide, contenu sont privés; le constructeur FC et les deux fonctions
ajouter et supprimer sont publics. On peut utiliser
des fonctions publiques depuis n'importe quelle classe. Seule la
classe courante peut utiliser les champs et les fonctions privés. Ceci
répond à un principe d'abstraction, puisqu'on n'accède à une classe
que par ses champs et ses fonctions publics. Cette abstraction est déjà
effectuée avec le regroupement des instructions en fonctions,
puisqu'il est interdit d'accéder à une variable locale de l'extérieur
d'une fonction. Mais avec les classes, le mécanisme dépasse la simple
portée du nom des variables, puisqu'on peut aussi rendre privés des
noms de champs ou de fonctions. C'est donc la tâche du programmeur de
séparer le code de son programme en unités (classes en Java) dont on
abstrait une interface (sa signature publique en Java). Graphiquement,
comme sur la figure 3.1, le module FC
(une classe) est divisée en une interface publique (le constructeur et
les deux fonctions publiques avec leurs signatures), et une boîte
noire destinée à implémenter cette interface (c'est-à-dire ses champs
et fonctions privés et leur code, ainsi que le code de son interface
publique).
Si on change la boîte noire (la partie implémentation) sans modifier
l'interface, tous les programmes utilisant la classe FC n'ont
pas besoin d'être modifiés. Par exemple, c'est le cas si on change
l'implémentation de cette classe en utilisant des listes de
caractères.
public class FC {
private Liste debut, fin;
public FC (int n) { debut = null; fin = null; }
public static void ajouter (char x, FC f) {
if (f.fin == null) f.debut = f.fin = new Liste (x);
else {
f.fin.suivant = new Liste (x);
f.fin = f.fin.suivant;
}
}
public static char supprimer (FC f) {
if (f.debut == null) throw new Error ("File Vide.");
else {
char res = f.debut.val;
if (f.debut == f.fin) f.debut = f.fin = null;
else f.debut = f.debut.suivant;
return res;
}
} |
Remarquons que pour respecter la signature de l'interface
publique, le constructeur FC est défini avec un paramètre, même
s'il est inutile.
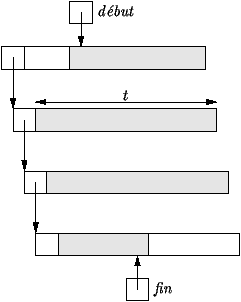
Figure 3.2 : File de caractères
La représentation des files de caractères par des listes chaînées est
coûteuse en espace mémoire. En effet, si un pointeur est représenté
par une mémoire de 4 ou 8 octets (adresse mémoire sur 32 ou 64 bits),
il faut 5 ou 9 octets par élément de la file, et donc 5N ou 9N
octets pour une file de N caractères. La représentation par tampon
circulaire est meilleure du point de vue de l'occupation mémoire.
Toutefois, elle est plus statique puisque, pour chaque file, il faut
réserver à l'avance la place nécessaire pour le tableau contenant le
tampon circulaire.
Introduisons une troisième réalisation possible de ces files. Au lieu
de représenter une file par la liste de tous les caractères la
constituant, nous allons regrouper les caractères par blocs contigus
de t caractères. Les premiers et derniers éléments de la liste
pourront être incomplets (comme indiqué dans la figure
3.2). Ainsi, si t=12, une file de N caractères
utilise environ (4+t) × N/t octets pour des adresses sur 32
bits, ce qui fait un incrément tout à fait acceptable de 1/3 d'octet
par caractère. (En Java, on peut être amené à doubler la taille de
chaque bloc, puisque les caractères prennent deux octets).
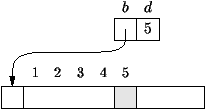
Une file de caractères sera alors décrite par un objet donnant le
nombre d'éléments de la file, les bases et déplacements des premiers
et derniers caractères de la file dans les premiers et derniers blocs
les contenant. Par base et déplacement d'un caractère, nous entendons
une référence vers un bloc de la liste contenant le caractère et son
adresse relative dans ce bloc comme indiqué sur la figure
3.3. La déclaration de la classe FC d'une
file de caractères s'effectue comme suit:
public class FC {
private int cc;
private Bloc debut_b, fin_b;
private int debut_d, fin_d;
public FC() { cc = 0; }
}
class Bloc {
final static int TAILLE = 12;
char[ ] contenu; Bloc suivant;
Bloc () { contenu = new char[TAILLE]; suivant = null; }
} |
Figure 3.3 : Adresse d'un caractère par base et déplacement
Pour ajouter un caractère à la file, on doit tester si le caractère
suivant est dans le même bloc ou s'il est nécessaire de prendre
le bloc suivant dans la liste des blocs. On alloue donc un nouveau
bloc dans le cas d'une file vide ou du franchissement d'un bloc.
public static void ajouter (char c, FC x) {
Bloc b;
if (x.cc == 0) {
b = new Bloc();
x.debut_b = b; x.debut_d = 0;
x.fin_b = b; x.fin_d = -1;
} else if (x.fin_d == Bloc.TAILLE - 1) {
b = new Bloc();
x.fin_b.suivant = b;
x.fin_b = b; x.fin_d = -1;
}
x.fin_b.contenu[++x.fin_d] = c;
++x.cc;
} |
Pour la suppression, il faut au contraire libérer un bloc si
le caractère supprimé (rendu en résultat) libère un bloc.
public static char supprimer (FC x) {
if (x.cc == 0)
throw new Error ("File Vide.");
else {
char res = x.debut_b.contenu[x.debut_d];
--x.cc;
++x.debut_d;
if (x.debut_d >= Bloc.TAILLE) {
x.debut_b = x.debut_b.suivant;
x.debut_d = 0;
}
return res;
}
} |
| 3.2 |
Interfaces et modules |
|
Supposons qu'un programme de gestion de terminaux utilise
des files de caractères, une pour chaque terminal. Grâce au principe
d'abstraction, il ne mélange pas la gestion des files de caractères
avec le reste de la logique du programme. Sa conception est donc
structurée, les files de caractères sont dans un module à
part. Le programme utilisant les files de caractères n'a pas besoin de
connaître tous les détails de l'implémentation de ces files. Il ne
connaît que la déclaration des types utiles dans la classe FC:
le nom de la classe et les trois fonctions pour initialiser une file
vide, ajouter un élément au bout de la file et retirer le premier
élément. On se contente de l'interface suivante:
public class FC {
public FC () {...}
/* Retourne une file vide */
public static void ajouter (char c, FC x) {...}
/* Ajoute c au bout de la file x */
public static char supprimer (FC x) {...}
/* Supprime le premier caractère c de x et rend c comme résultat */
/* Si x est vide, l'erreur "File Vide" est levée */
} |
Les files de caractères ne seront manipulées qu'à travers
cette interface. Pas question de connaître la structure interne de ces
files, ni de savoir si elles sont organisées par de simples listes,
des tableaux circulaires ou des blocs enchaînés. On dira que le
programme utilisant des files de caractères à travers l'interface
précédente importe cette interface. Les corps des fonctions sur
les files sont dans la partie implémentation du module des
files de caractères. Dans l'interface d'un module, il n'y a donc que
les types, les champs ou les fonctions que l'on veut exporter ou
rendre publiques. Il est bon d'y commenter la fonctionnalité de chaque
élément pour en comprendre sa signification, par la simple lecture de
l'interface. Dans un module, il y a donc toute une partie cachée
comprenant les types et les corps des procédures ou des fonctions que
l'on veut rendre privées. C'est ce qu'on appelle le principe
d'encapsulation.
Comment y arriver en Java? Comme déjà vu, le plus simple est de se
servir des modificateurs d'accès dans la déclaration des variables ou
des méthodes de la classe FC. Le qualificatif private
d'un champ ou d'une fonction signifie que seuls les instructions à
l'intérieur de la classe où ce champ ou cette fonction sont définis
pourront les accéder. Au contraire public dit qu'un champ est
accessible par toutes les classes. L'option par défaut est de rendre
public les champs à l'intérieur du paquetage où il est défini
(cf. plus loin), comme cela était le cas pour les champs de la classe
Bloc)
On peut avoir à cacher non seulement le code des procédures réalisant
l'interface, mais aussi des variables et des fonctions internes, en
composant les modules pour en fabriquer d'autres. Supposons dans notre
exemple, que, pour être efficace (ce qui peut être le cas pour piloter
un périphérique), nous voulions avoir notre propre stratégie
d'allocation pour les blocs. On construit alors une liste des blocs
libres listeLibre à l'initialisation du chargement de la classe
FC et on utilise des fonctions nouveauBloc et libererBloc comme suit:
class FC {
private int cc;
private Bloc debut_b, fin_b;
private int debut_d, fin_d;
public FC () { cc = 0; }
public static void ajouter (char c, FC x) {
Bloc b;
if (x.cc == 0) {
b = nouveauBloc();
x.debut_b = b; x.debut_d = 0;
x.fin_b = b; x.fin_d = -1;
} else if (x.fin_d == Bloc.TAILLE - 1) {
b = Bloc.allouer();
x.fin_b.suivant = b;
x.fin_b = b; x.fin_d = -1;
}
x.fin_b.contenu[++x.fin_d] = c;
++x.cc;
}
public static char supprimer (FC x) {
if (x.cc == 0)
throw new Error ("File Vide.");
else {
char res = x.debut_b.contenu[x.debut_d];
--x.cc;
++x.debut_d;
if (x.cc <= 0)
Bloc.liberer (x.debut_b);
else if (x.debut_d >= Bloc.TAILLE) {
Bloc b = x.debut_b;
x.debut_b = x.debut_b.suivant;
x.debut_d = 0;
Bloc.liberer (b);
}
return res;
}
}
}
class Bloc {
final static int TAILLE = 12;
char[ ] contenu; Bloc suivant;
Bloc () { contenu = new char[TAILLE]; suivant = null; }
private final static int NB_BLOCS = 1000;
private static Bloc listeLibre;
static {
listeLibre = null;
for (int i=0; i < NB_BLOCS; ++i) {
Bloc b = new Bloc();
b.suivant = listeLibre;
listeLibre = b;
}
}
private static Bloc allouer () {
Bloc b = listeLibre;
listeLibre = listeLibre.suivant;
b.suivant = null;
return b;
}
private static void liberer (Bloc b) {
b.suivant = listeLibre;
listeLibre = b;
}
} |
La variable listeLibre reste cachée, puisque cette
variable n'est pas définie dans l'interface des files de
caractères. Il en est de même pour les fonctions d'allocation et de
libération des blocs. Faisons trois remarques. Premièrement, il est
fréquent qu'un module nécessite une procédure d'initialisation. En
Java, on le fait en mettant quelques instructions, précédées du
mot-clé static dans la déclaration de la classe. Ces
instructions ne seront exécutées qu'une seule fois au chargement de la
classe. (Une classe est chargée lors du premier accès à un élément de
cette classe). Deuxièmement, pour ne pas compliquer le programme,
nous ne testons pas le cas où la liste des blocs libres devient
vide. Alors l'allocation d'un nouveau bloc libre devient
impossible. Troisièmement, il y a une belle structure hiérarchique des
divers modules d'un programme: le driver se sert des files de
caractères, lesquelles se servent d'un module d'allocation de blocs.
Pour résumer, un module contient deux parties: une interface exportée
qui contient les constantes, les types, les variables et la signature
des fonctions ou procédures que l'on veut rendre publiques, une partie
implémentation qui contient la réalisation des objets de l'interface.
L'interface est la seule porte ouverte vers l'extérieur. Dans la
partie implémentation, on peut utiliser tout l'arsenal possible de la
programmation. On ne veut pas que cette partie soit connue de son
utilisateur. Si on arrive à ne laisser public que le strict nécessaire
pour utiliser un module, on aura grandement simplifié la structure
d'un programme. Il faut donc bien faire attention aux interfaces, car
une bonne partie de la difficulté de la programmation réside dans le
bon choix des interfaces.
Découper un programme en modules permet aussi la réutilisation des
modules, la construction hiérarchique des programmes puisqu'un module
peut lui-même être aussi composé de plusieurs modules, le
développement indépendant de programmes par plusieurs personnes dans
un même projet de programmation. Il facilite les modifications, si les
interfaces restent inchangées. Ici, nous insistons sur la
structuration des programmes, car tout le reste n'est que corollaire.
Tout le problème de la modularité se résume à isoler des parties de
programme comme des boîtes noires, dont les seules parties visibles à
l'extérieur sont les interfaces. Bien définir un module assure la
sécurité dans l'accès aux variables ou aux procédures, et est un bon
moyen de structurer la logique d'un programme. Une deuxième partie de
la programmation consiste à assembler les modules de façon claire.
Beaucoup de langages de programmation ont une notion explicite de
modules et d'interfaces, par exemple Ada, Caml-light, Cedar, Clu,
Mesa, Modula-2, Modula-3, et Oberon. Certains (comme SML/NJ et Ocaml)
ont même des modules paramétriques très sophistiqués. En C ou C++, il
n'y a aucune notion de module, et on utilise les fichiers include pour simuler les interfaces des modules, en faisant
coïncider les notions de module et de compilation séparée.
En Java, la notion de modularité est plus dynamique et reportée dans
le langage de programmation avec les modificateurs d'accès. Il n'y a
pas de phase d'éditions de liens permettant de faire coïncider
interfaces et implémentations. Seul le chargeur dynamique (le ClassLoader) ou l'interpréteur (la JVM, c'est-à-dire la machine
virtuelle de Java) font quelques vérifications. Il existe une notion
d'interfaces avec le mot-clé Interface et de classes
implémentant ces interfaces, mais ces notions sont plutôt réservées à
la construction de classes paramétrées ou à la gestion dynamique
simultanée de plusieurs implémentations pour une même interface.
| 3.3 |
Structure de l'espace des noms, paquetages |
|
Il existe aussi une autre forme de modularité en se servant de la
restriction dans l'espace des noms. Nous avons vu que pour accéder à
des variables ou à des fonctions, on pouvait qualifier leurs noms par
le nom de la classe (ou d'un objet pour les méthodes
dynamiques). Ainsi on peut écrire Liste.ajouter, FC.TAILLE, args.length(), System.out.print. Mais on peut
aussi préfixer, les noms par un nom de paquetage. Un paquetage (package) permet de regrouper un ensemble de classes qui ont des
fonctionnalités proches, par exemple les appels-système, les
entrées/sorties, etc. Un paquetage est associé à un répertoire du
système de fichiers, dont les classes sont des fichiers. On peut
spécifier le paquetage où se trouve une classe en la précédent par
l'instruction
où id1, id2, ...idk sont des
identificateurs quelconques. Pour accéder à une classe d'un tel
paquetage, le nom de cette classe est précédée par le nom complet du
paquetage dont elle fait partie. Par exemple, si on veut utiliser
la classe FC du sous-paquetage listes de mon paquetage
ma_librairie, on écrit:
|
ma_librairie.listes.FC f = new ma_librairie.listes.FC(); |
On peut revenir à une notation plus brève (qui évite de mettre le nom
complet du paquetage) en utilisant l'instruction import en tête
d'un programme.
import ma_librairie.listes.FC;
import java.io.*;
import java.lang.*;
import java.util.*; |
Le dernier champ du paquetage importé est soit un nom de
classe, soit un astérisque (*). Dans ce dernier cas, ce sont
toutes les classes contenues dans le répertoire désigné qui sont
importées.
L'emplacement des paquetages dépend de deux paramètres: le nom
id1.id2.....idk qui désigne, dans
le système Unix, l'emplacement
id1/id2/.../idk dans l'arborescence
des répertoires du système de fichiers; la variable d'environnement
CLASSPATH qui donne une suite de racines possibles pour
l'arborescence considérée. On considèrera alors le premier paquetage
trouvé dans l'ordre de la liste des racines possibles. Les paquetages
peuvent aussi se trouver dans une forme compressée des répertoires,
très utilisée en Java, les fichiers .jar (java
archives), qui contiennent en un seul fichier toute une
arborescence de paquetages (cf. la commande Unix jar). Les
fichiers .zip peuvent aussi être utilisés. Pour donner une
valeur à CLASSPATH, on utilise, par exemple, la commande Unix:
|
% setenv CLASSPATH ".:$HOME/if431/DM1:/users/profs/info/chassignet/Jaxx" |
Enfin, on peut aussi trouver le paquetage à l'endroit des paquetages
standards (souvent regroupés dans un grand ficher .jar ou .zip). C'est le cas pour les paquetages java.util qui contient
des classes standards pour les tables, les piles, les tableaux de
taille variable, etc, pour java.io qui contient les classes
d'entrées-sorties, pour java.awt qui contient les classes
graphiques, java.math qui contient les classes mathématiques.
Le répertoire contenant un fichier source .java est aussi
considéré comme un paquetage anonyme. Un fichier source ne commençant
pas par une instruction package est considéré comme déclarant
des classes dans le paquetage anonyme, c'est-à-dire dans le répertoire
courant.
Les paquetages interviennent aussi dans les droits d'accès aux champs
des classes. Plus exactement, trois types d'accès sont possibles pour
les membres d'une classe:
- public en préfixant un champ par public pour permettre
l'accès depuis toutes les classes.
- privé en préfixant un champ par private pour restreindre
l'accès aux seules expressions ou fonctions dans la classe courante.
- amical en ne mettant aucun préfixe devant la déclaration d'un
champ pour autoriser l'accès depuis toutes les classes du même
paquetage (c'est donc l'accès par défaut).
Exercice 17 Montrer qu'on peut accéder facilement aux champs ou fonctions des
classes compilées dans le même répertoire.
| 3.4 |
Compilation séparée et librairies |
|
La compilation d'un programme consiste à fabriquer le binaire
exécutable par le processeur de la machine. Pour des programmes de
plusieurs milliers de lignes, il est bon de les découper en des
fichiers compilés séparément. En Java, le code généré est indépendant
de la machine qui l'exécute, ce qui permet de l'exécuter sur toutes
les architectures à travers le réseau. Le code (byte-code) est
interprété par un interpréteur dépendant lui de l'architecture
sous-jacente, la machine virtuelle Java (encore appelée JVM pour en
anglais Java Virtual Machine). Les fichiers de byte-code
ont le suffixe .class, les fichiers sources ayant eux d'habitude
le suffixe .java. Pour compiler un fichier source sous un
système Unix, la commande:
permet d'obtenir le fichier de byte-code de nom FC.class qui peut être utilisé par d'autres modules compilés
indépendamment. Supposons qu'un fichier TTY.java contenant un
gestionnaire de terminaux utilise les fonctions sur les files de
caractères. Ce programme contiendra des lignes du genre:
class TTY {
FC in, out;
TTY () { in = new FC(); out = new FC(); }
static int Lire (FC in) { ··· }
static void Imprimer (FC out) { ··· }
} |
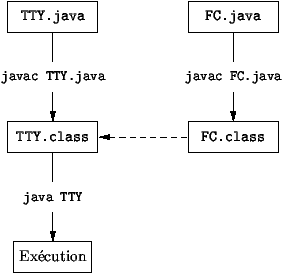
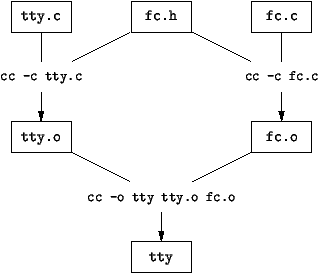
Figure 3.4 : Compilation séparée
En Unix, on devra compiler séparément TTY.java et on lancera la
machine Java sur TTY.class par les commandes:
% javac TTY.java
% java TTY |
Remarquons que le suffixe .class ne doit curieusement
pas apparaître dans la deuxième commande. La dernière commande cherche
la fonction publique main dans la classe TTY.class et
démarre la machine virtuelle Java sur cette fonction. Les diverses
classes utilisées sont chargées au fur et à mesure de leur
utilisation. Contrairement à beaucoup de langages de programmation, il
n'y a pas (pour le meilleur et pour le pire) de phase d'édition de
liens en Java. Tout se fait dynamiquement. Graphiquement, les phases
de compilation sont représentées par la figure
3.4.
| 3.5 |
Dépendances entre modules |
|
Lors de l'écriture d'un programme composé de plusieurs modules, il est
commode de décrire les dépendances entre modules et la manière de
reconstruire les binaires exécutables. Ainsi on peut recompiler le
strict nécessaire en cas de modification d'un module. Dans l'exemple
de notre gestionnaire de terminaux, nous voulons indiquer que les
dépendances induites par la figure 3.5 pour
reconstruire le code objet TTY.class. La description des
dépendances varie selon le système. La commande javac fait
l'analyse de dépendances et compile ce qui est nécessaire. De même, la
commande Run ou Compile en CodeWarrior sur Mac. De manière
plus générale sous le système Unix, on utilise des Makefile et
la commande make.
Supposons pour un moment notre programme écrit en C, avec un fichier
d'interface fc.h. Le fichier de dépendances serait ainsi écrit:
tty: tty.o fc.o
cc -o tty tty.o fc.o
tty.o: tty.c fc.h
cc -c tty.c
fc.o: fc.c fc.h
cc -c fc.c |
Figure 3.5 : Dépendances dans un
Makefile
Après ``:'', il y a la liste des fichiers dont dépend
le but mentionné au début de la ligne. Dans les lignes suivantes, il y
a la suite de commandes à effectuer pour obtenir le fichier but. La
commande Unix make considère le graphe des dépendances et
calcule les commandes nécessaires pour reconstituer le fichier but. Si
les interdépendances entre fichiers sont représentés par les arcs d'un
graphe dont les sommets sont les noms de fichier, on fait un tri
topologique sur le graphe de dépendances pour trouver la suite des
commandes à effectuer.
| 3.6 |
Un exemple de module en C |
|
Comme en Java, le langage C n'a pas de système de modules. Nous
reprenons l'exemple des files de caractères (en fait telles qu'elles
se trouvaient dans le système Unix version 7 pour les gestionnaires de
terminaux). C'est aussi l'occasion de constater comment la
programmation en C permet certaines acrobaties, peu recommandables car
on aurait pu suivre la technique d'adressage des caractères dans les
blocs comme en Java. La structure des files est légèrement différente
car on adresse directement les caractères dans un bloc au lieu du
système base et déplacement. Le débordement de bloc est testé en
regardant si on est sur un multiple de la taille d'un bloc, car on
suppose le tableau des blocs aligné sur un multiple de cette taille.
Le fichier interface fc.h est
#define NCLIST 80 /* max total clist size */
#define CBSIZE 12 /* number of chars in a clist block */
#define CROUND 0xf /* clist rounding: sizeof(int + CBSIZE-1 */
/*
* A clist structure is the head
* of a linked list queue of characters.
* The characters are stored in 4-word
* blocks containing a link and several characters.
* The routines fc_get and fc_put
* manipulate these structures.
*/
struct clist
{
int c_cc; /* character count */
char *c_cf; /* pointer to first char */
char *c_cl; /* pointer to last char */
};
struct cblock {
struct cblock *c_next;
char c_info[CBSIZE];
};
typedef struct clist *fc_type;
int fc_put(char c, fc_type p);
int fc_get(fc_type p);
void fc_init(void); |
Dans la partie implémentation qui suit, on remarque l'emploi
de la directive static (celle de C, et non de Java!) qui permet
de cacher à l'édition de liens des variables, procédures ou fonctions
privées qui ne seront pas considérées comme externes. Il est possible
en C de cacher la représentation des files, en ne déclarant le type
fc_type que comme un pointeur vers une structure clist
non définie. Les fonctions retournent un résultat entier qui permet
de retourner des valeurs erronées comme -1. Le fichier fc.c
est
#include <stdlib.h>
#include <fc.h>
static struct cblock cfree[NCLIST];
static struct cblock *cfreelist;
int fc_put(char c, fc_type p)
{
struct cblock *bp;
char *cp;
register s;
if ((cp = p->c_cl) == NULL || p->c_cc < 0 ) {
if ((bp = cfreelist) == NULL)
return(-1);
cfreelist = bp->c_next;
bp->c_next = NULL;
p->c_cf = cp = bp->c_info;
} else if (((int)cp & CROUND) == 0) {
bp = (struct cblock *)cp - 1;
if ((bp->c_next = cfreelist) == NULL)
return(-1);
bp = bp->c_next;
cfreelist = bp->c_next;
bp->c_next = NULL;
cp = bp->c_info;
}
*cp++ = c;
p->c_cc++;
p->c_cl = cp;
return(0);
}
int fc_get(fc_type p)
{
struct cblock *bp;
int c, s;
if (p->c_cc <= 0) {
c = -1;
p->c_cc = 0;
p->c_cf = p->c_cl = NULL;
} else {
c = *p->c_cf++ & 0xff;
if (--p->c_cc<=0) {
bp = (struct cblock *)(p->c_cf-1);
bp = (struct cblock *) ((int)bp & ~CROUND);
p->c_cf = p->c_cl = NULL;
bp->c_next = cfreelist;
cfreelist = bp;
} else if (((int)p->c_cf & CROUND) == 0){
bp = (struct cblock *)(p->c_cf-1);
p->c_cf = bp->c_next->c_info;
bp->c_next = cfreelist;
cfreelist = bp;
}
}
return(c);
}
void fc_init()
{
int ccp;
struct cblock *cp;
ccp = (int)cfree;
ccp = (ccp+CROUND) & ~CROUND;
for(cp=(struct cblock *)ccp; cp <= &cfree[NCLIST-1]; cp++) {
cp->c_next = cfreelist;
cfreelist = cp;
}
} |
On construit pour tout module deux fichiers fc.mli (pour ML
interface) et fc.ml (le fichier d'implémentation du module). Le
premier est un fichier d'interface dans lequel on donne la signature
de tous les types, variables ou fonctions exportées. Par exemple:
(* Files de caractères *)
type t
(* Le type des files de caractères *)
exception FileVide
(* Levée quand supprimer est appliquée à une file vide. *)
val vide: unit -> t
(* Retourne une nouvelle file, initialement vide. *)
val ajouter: char -> t -> t
(* ajouter c x ajoute le caractère c à la fin de la file x. *)
val supprimer: t -> char
(* supprimer x enlève et retourne le premier élément de la file x
ou lève l'exception FileVide si la queue est vide. *) |
Le deuxième contient l'implémentation des files de
caractères, où on fournit les structures de données ou le code
correspondant à chaque déclaration précédente:
type t = {mutable cc: int;
mutable debut_b: liste_de_blocs; mutable debut_d: int;
mutable fin_b: liste_de_blocs; mutable fin_d: int} and
liste_de_blocs = Nil | Cons of bloc and
bloc = {contenu: string; mutable suivant: liste_de_blocs};;
exception FileVide;;
let taille_bloc = 12;;
let vide() = {cc = 0; debut_b = Nil; debut_d = 0; fin_b = Nil; fin_d = 0};;
let ajouter c x =
let nouveau_bloc() =
Cons {contenu = String.make taille_bloc ' '; suivant = Nil} in
if x.cc = 0 then begin
let b = nouveau_bloc() in
x.debut_b <- b; x.debut_d <- 0;
x.fin_b <- b; x.fin_d <- -1;
end else if x.fin_d = taille_bloc - 1 then begin
let b = nouveau_bloc() in
(match x.fin_b with
Cons r -> r.suivant <- b
| Nil -> ()
);
x.fin_b <- b; x.fin_d <- -1;
end;
x.fin_d <- x.fin_d + 1;
(match x.fin_b with
Cons r -> r.contenu.[x.fin_d] <- c
| Nil -> ()
);
x.cc <- x.cc + 1;
x;;
let supprimer x =
if x.cc = 0 then
raise FileVide
else match x.debut_b with
Nil -> failwith "Cas impossible"
| Cons r -> let res = r.contenu.[x.debut_d] in
x.cc <- x.cc - 1;
x.debut_d <- x.debut_d + 1;
if x.debut_d >= taille_bloc then begin
x.debut_b <- r.suivant;
x.debut_d <- 0;
end;
res;; |
Dans un deuxième module, par exemple un gestionnaire de
terminaux dont le code se trouve dans un fichier tty.ml, on
peut utiliser les noms du module fc.mli en les qualifiant par
le nom du module suivi du symbole (.) point.
let nouveau_tty =
let x = Fc.vide() in
...
let y = Fc.ajouter c x .... |
Si on n'a pas envie d'utiliser cette notation longue, on supprime
le préfixe avec la directive suivante en tête de tty.ml.
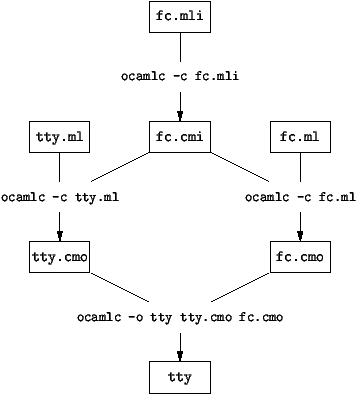
Les dépendances entre modules se font comme dans le cas de C. On se sert de
la commande make de Unix et du makefile suivant. Remarquons
que les fichiers .ml se compilent en fichiers .cmo, les
fichiers .mli en .cmi, et que l'on finit avec un fichier
tty directement exécutable.
tty: tty.cmo fc.cmo
ocamlc -o tty tty.cmo fc.cmo
tty.cmo: tty.ml fc.cmi
ocamlc -c tty.ml
fc.cmo: fc.ml
ocamlc -c fc.ml
fc.cmi: fc.mli
ocamlc -c fc.mli |
Figure 3.6 : Dépendances entre modules Caml
Enfin, en Caml, on n'est pas forcé de définir un fichier d'interface,
auquel cas le compilateur générera automatiquement un fichier
.cmi en supposant toutes les variables et fonctions publiques
dans le module d'implémentation. Toutefois, c'est plus sûr de définir
soi-même les fichiers d'interface.
| 3.8 |
Programmation par objets |
|
La programmation par objets est devenue très populaire. C'est
maintenant un argument de vente pour les langages de programmation,
puisque tous les langages modernes ont une extension objets.
Pourtant, ce style de programmation n'est pas facile à définir. La
théorie des types correspondante a fait couler beaucoup d'encre. Si on
arrive à présent à mieux la comprendre, les problèmes pratiques
associés ne sont pas encore vraiment résolus. En demandant à des
informaticiens (chevronnés) ce qu'est la programmation par objets, on
obtient des réponses variées: un objet est une boîte avec des boutons,
un objet est un enregistrement avec des champs fonctionnels, un objet
est un module, un objet a un état mémoire, un objet est réutilisable,
un objet sert à faire de l'héritage, un objet permet de faire de la
liaison retardée, etc. Un non-informaticien m'a une fois bien résumé
la situation en remarquant qu'un objet était un peu tout et n'importe
quoi! Cependant, nous nous lançons dans une tentative d'explication.
| |
modification des |
modification du |
| |
données |
programme |
| programmation |
|
|
| procédurale |
changement global |
changement local |
| programmation |
|
|
| par objets |
changement local |
changement global |
Figure 3.7 : Programmation procédurale, programmation par objets
La programmation classique a un caractère procédural. Les instructions
d'un programme sont regroupées en fonctions (encore appelées
procédures); à partir des fonctions, on construit d'autres
fonctions. Dans la programmation par objets, la programmation est
organisée autour des données. Une donnée contient ses valeurs et les
fonctions (encore appelées méthodes) opérant sur elle. Dans le style
procédural, si on rajoute quelques champs à un type de donnée, on doit
faire un changement global dans toutes les fonctions qui agissent sur
ce type de donnée. Dans le style par objets, on ne fait qu'un
changement local en créant une sous-classe (avec les méthodes
associées) de la classe correspondant à ce type de donnée. Mais dans
la programmation procédurale, si on modifie une fonction, le
changement est local à cette fonction, alors que dans la programmation
par objets, le changement doit être effectué dans toutes les méthodes
de même nom que cette fonction. Ceci est résumé sur la
figure 3.7.
La programmation par objets a une deuxième caractéristique: c'est la
notion de programmation incrémentale. Comme l'organisation du
programme est centrée sur les données, on peut se contenter de faire
suivre son évolution par spécialisation de ses différentes classes de
données à partir de classes plus générales. On ne modifie pas un
programme, on ne fait qu'ajouter des incréments (à une bibliothèque de
fonctions pré-existantes). L'exemple typique est celui d'une boîte à
outils graphique, où les données (les fenêtres, boutons, barres de
défilement) ont beaucoup de paramètres et où on ne code principalement
que des incréments par rapport à des modèles de classes graphiques
fournies en standard. Ainsi les fenêtres à coins arrondis sont une
spécialisation des fenêtres rectangulaires, et beaucoup des fonctions
valables sur les fenêtres rectangulaires restent valides sur les
fenêtres à coins arrondis. Si nécessaire, on redéfinira quelques
fonctions, telles que celle pour l'affichage d'une fenêtre ou
l'interaction avec la souris. La programmation incrémentale fonctionne
donc bien dans une univers où toutes les données sont proches, et où
de petites modifications sont suffisantes pour définir de nouvelles
données.
Troisièmement, on associe souvent la notion de sous-typage au
style de programmation par objets. Il n'y a pas la place ici pour
traiter du sous-typage, notion fine de la programmation. Disons
simplement que, si T est un sous-type de T' (écrivons T £
T'), alors si une variable ou une fonction est de type T, elle peut
aussi être considérée de type T', et donc être utilisée dans tout
contexte où une expression de type T' est attendue. En Java, par
exemple, on a byte £ short £ int, char £ int, etc. Nous savons aussi qu'on a C £ Object pour toute classe C. Tout le problème du sous-typage
consiste à étudier son interaction avec les différentes constructions
du langage de programmation, c'est-à-dire avec les fonctions et les
classes en Java.
Enfin, avant d'aller plus loin dans la programmation par objets,
rappelons qu'un objet est techniquement l'instance d'une classe,
c'est-à-dire une entité de type classe. En Java, c'est la seule
manière (avec les tableaux) de faire des données composites. Les
objets ont un état (qui donne la valeur de leurs champs de données) et
un ensemble de méthodes attachées. Il y a deux types de méthodes: les
méthodes f, g, etc, statiques qui sont invoquées par les
expressions de la forme C.f, C.g si C est le nom de la classe où
elles sont définies; les méthodes f', g', etc, non statiques, qui
sont appelées par les expressions o.f', o.g', si o est l'objet
dont elles sont membres. A priori, ce deuxième type de méthodes parait
superflu. Pourtant, on est là au coeur de la programmation par
objets, car l'idée est qu'on ne connait pas a priori la
définition de f', g', etc. Nous verrons plus tard la notion de
spécialisation de méthodes, qui correspond à cette notation.
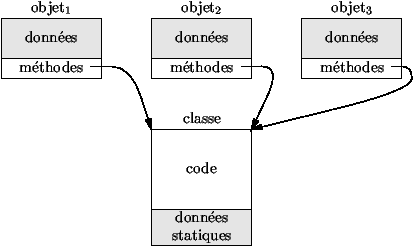
Figure 3.8 : Trois objets d'une même classe
D'un point de vue implémentation, un objet a la représentation de la
figure 3.8. Les champs de données sont différents pour
les objets d'une même classe. Seuls les champs de données statiques
sont uniquement représentés dans la classe. La partie code peut être
regroupée au niveau de la classe pour les méthodes (statiques et non
statiques), puisque toutes les méthodes partagent un même code. En
fait, tout objet a un point d'entrée pour chaque méthode non statique,
ce point d'entrée n'est qu'un pointeur vers la zone de code unique
pour la classe. Pour résumer, un objet est un enregistrement avec des
champs de données et des champs fonctionnels (représentés par un
simple pointeur vers la zone de code) pour les méthodes.
| 3.9 |
Hiérarchie des classes et sous-typage |
|
Considérons l'exemple classique des points colorés sur R2, où
chaque point a deux coordonnées x et y. On considère deux
fonctions statiques translation et rotation qui font les
opérations correspondantes sur le point p pris en argument.
class Point {
double x, y;
Point () { }
Point (double x0, double y0) { x = x0; y = y0; }
static void translation (Point p, double dx, double dy) {
p.x = p.x + dx; p.y = p.y + dy;
}
static void rotation (Point p, double theta) {
double x = p.x * Math.cos(theta) - p.y * Math.sin(theta);
double y = p.x * Math.sin(theta) + p.y * Math.cos(theta);
p.x = x; p.y = y;
} } |
Considérons la classe PointC des points colorés, définie comme une
sous-classe de la classe Point, grâce au mot-clé extends:
class PointC extends Point {
final static int JAUNE = 0, ROUGE = 1;
int c;
PointC (double x0, double y0, int col) { super(x0, y0); c = col;}
public static void main (String[ ] args) {
PointC p = new PointC(3, 4, JAUNE) ;
rotation (p, Math.PI);
} } |
Un point coloré p a un champ supplémentaire c pour sa
couleur. Les fonctions de translation et de rotation, qui ne font pas
intervenir la couleur, restent les mêmes. La sous-classe PointC hérite donc ces deux méthodes, ainsi que les deux champs x
et y, et on peut appliquer translation et rotation à
des points colorés, comme cela se produit dans le programme principal
précédent, où il y a donc une conversion implicite du point coloré p
en un point non coloré pour le passer en argument de la fonction rotation.
Au contraire, pour passer d'un point à un point coloré, il faut faire
une conversion explicite. Considérons une autre définition de la
fonction de rotation qui rend le point modifié comme résultat. Alors
cette fonction et main sont modifiées, chacune dans sa classe,
comme suit:
static Point rotation (Point p, double theta) {
double x = p.x * Math.cos(theta) - p.y * Math.sin(theta);
double y = p.x * Math.sin(theta) + p.y * Math.cos(theta);
p.x = x; p.y = y;
return p;
}
...
public static void main (String[ ] args) {
PointC p = new PointC(3, 4, JAUNE) ;
p = (PointC) rotation (p, Math.PI);
} |
Comme la fonction rotation retourne un point pas
forcément coloré, on doit tester dynamiquement si ce point est coloré,
ce qui est fait par la conversion explicite de son résultat avant de
l'affecter à la variable p de type point coloré. Ce test peut
échouer et lever l'exception ClassCastException. Cela n'est pas
le cas dans notre exemple.
Modifions encore notre programme, et supposons à présent que le point
retourné par la fonction rotation est un nouveau point. Alors
cette fonction ne fait plus d'effet de bord sur son argument (ce qui
est bien en général). Son code et celui de main deviennent:
static Point rotation (Point p, double theta) {
double x = p.x * Math.cos(theta) - p.y * Math.sin(theta);
double y = p.x * Math.sin(theta) + p.y * Math.cos(theta);
return new Point (x, y);
}
...
public static void main (String[ ] args) {
PointC p = new PointC (3, 4, JAUNE) ;
p = (PointC) rotation (p, Math.PI);
} |
L'exécution de main lève maintenant l'exception
ClassCastException, puisque la valeur retournée par la
fonction rotation est un point non coloré. Sa conversion en
point coloré est impossible, puisque son champ couleur n'existe pas.
En résumé, il y a conversion implicite d'un objet d'une sous-classe en
objet de sa sur-classe. Mais il faut convertir explicitement un objet
d'une classe pour le spécialiser en un objet d'une sous-classe. Cette
conversion n'est possible que s'il est déjà (à conversion implicite
près) un objet de cette sous-classe. On peut le tester dynamiquement,
car tout objet garde un indicateur de la classe dans laquelle il a été
créé. Donc, en Java, si la classe C est une sous-classe de la classe
D, alors C est un sous-type de D (C £ D). Et si C ®
C' désigne le type des fonctions de C dans C', et D ® D' le
type des fonctions de D dans D', on a
D £ C et C' £ D' Þ C ® C' £ D ® D'
Cette proposition, vraie dans tous les systèmes de sous-typage,
indique que le sous-typage se conduit différemment dans les arguments
d'une fonction (contravariance) et dans son résultat
(covariance). Plus simplement, dans l'exemple précédent, on retrouve
cette formule on considérant C=PointC, D=Point, C'=
D' =void (dans le premier cas) et C'= D' =Point (dans le
deuxième cas).
Quand une classe est une sous-classe d'une autre, on dit aussi qu'elle
hérite de sa surclasse. En Java, la hiérarchie entre les classes a une
structure arborescente. Toute classe n'a qu'une seule classe parente.
On dit encore que l'héritage est simple. Il existe des langages de
programmation où une classe peut hériter de plusieurs classes
(héritage multiple), par exemple Smalltalk, C++, Ocaml, mais alors
l'implémentation de ces langages est plus délicate, car, dans les
langages à héritage simple, on connait l'emplacement de chacun de ses
champs avant l'exécution du programme. La classe racine de la
hiérarchie des classes est la classe Object. (En Java, les
interfaces permettent de faire de l'héritage multiple; cette partie du
langage a une implémentation moins efficace).
Une remarque un peu plus subtile consiste à noter que le typage de
Java nous force à faire une conversion explicite de type dans la
deuxième définition de rotation. En fait, la fonction rotation a un type " C£ Point. C × double ® C, elle peut prendre un argument de type C arbitraire
sous-type de Point et un réel double comme deuxième
argument, puis retourner un objet du type C. Avec un tel système de
type, on sait que la fonction retourne un point coloré si l'argument
est de type point coloré, et la conversion explicite devient inutile
dans la fonction main. Une autre solution pour typer rotation consiste à donner le type á x:int, y:int,
rñ × double ® á x:int, y:int,
rñ où r est une variable de type désignant la
possibilité de rajouter des champs (type d'une rangée). Alors à
nouveau sans conversion de type, on peut assurer que le retour de la
fonction de rotation redonne bien un point coloré si on lui passe en
argument un point coloré. Cette solution, se servant de sous-typage
structurel, est utilisée en Ocaml. Enfin, on peut remarquer qu'on a
plus de difficulté à typer la troisième version des points colorés
(qui fait une rotation sans effet de bord). La raison est qu'on crée
alors un nouvel objet et que celui a alors le type Point. Pourtant, on peut arriver à lui donner un des deux types
précédents si on dispose d'une opération de clonage des objets, qui
copie un objet existant avec son type. On retrouve alors les deux
solutions précédentes pour typer la troisième version de notre
fonction de rotation. Cette opération de clonage n'existe pas en Java.
Chacune de ces solutions pour résoudre le problème du sous-typage pose
des problèmes pour calculer automatiquement le type (inférence de type
en Ocaml).
| 3.10 |
Notation objet et liaison tardive |
|
Reprenons l'exemple des points colorés en utilisant des méthodes non
statiques et en utilisant la notation objet pour l'invocation des
fonctions de translation et de rotation:
class Point {
double x, y;
Point () { }
Point (double x0, double y0) { x = x0; y = 0; }
Point translation (double dx, double dy) {
x = x + dx; y = y + dy; return this;
}
Point rotation (double theta) {
double x1 = x * Math.cos(theta) - y * Math.sin(theta);
double y1 = x * Math.sin(theta) + y * Math.cos(theta);
x = x1; y = y1;
return this;
} }
class PointC extends Point {
final static int JAUNE = 0, ROUGE = 1;
int c;
PointC (double x0, double y0, int col) { x = x0; y = y0; c = col;}
public static void main (String[ ] args) {
PointC p = new PointC(3, 4, JAUNE) ;
p = (PointC) p.rotation(Math.PI);
} } |
Pour les points colorés, la notation objet n'est pas vraiment
nécessaire. Certains aiment l'utiliser pour son aspect compact. Mais
l'intérêt de cette écriture réside dans la notion de liaison
tardive. En effet, lorsqu'on écrit o.f pour appeler la méthode f
de l'objet o, on ne fixe pas vraiment la classe où f est défini
(contrairement à la notation utilisée pour les méthodes statiques). La
règle est d'invoquer la méthode f de la classe la plus spécifique
(c'est-à-dire la plus petite) dont l'objet o est une
instance. Prenons par exemple le cas de la méthode toString de
transformation en chaîne de caractères, utilisée dans les fonctions
d'impression. En Java, par convention,
est toujours équivalent à
|
System.out.println (p.toString()); |
sauf si p est déjà une chaîne. Il y a donc un appel de la méthode
toString pour effectuer l'impression de p. Cette méthode
est déjà définie dans la classe Object. Mais, on veut la
redéfinir dans toutes les classes pour obtenir un format d'impression
compréhensible, et notamment dans notre cas des points possiblement
colorés:
class Point {
double x, y;
...
public String toString() { return "(" + x + ", " + y + ")"; }
}
class PointC extends Point {
final static int JAUNE = 0, ROUGE = 1;
int c;
...
public String toString() { return "(" + x + ", " + y + ", " + c + ")"; }
public static void main (String[ ] args) {
PointC p = new PointC(3, 4, JAUNE) ;
System.out.println (p);
Point q = new Point (1, 8) ;
System.out.println (q);
} } |
Les implémenteurs de Java ont écrit le code de la fonction System.out.println sans connaître la définition de la méthode toString pour les points, éventuellement colorés. La notation
objet permet de faire cette liaison tardive. Les deux appels
de println invoquent deux méthodes toString
différentes, puisque, pour p, on se sert de la méthode des points
colorés et pour q de celle des points non colorés. Remarquons qu'on
pourait se dispenser de la liaison tardive en passant en argument de
println la fonction toString, mais cela est impossible
dans un langage non fonctionnel comme Java. L'écriture compacte de la
liaison tardive a ses adeptes, mais il faut remarquer que cela
entraine des difficultés de lisibilité du code, par exemple pour
retrouver la fonction véritablement invoquée au milieu d'une grande
hiérarchie de classes.
En résumé, la programmation par objets implique une forme de
modularité, puisqu'on est amené à regrouper dans un objet les données
et les fonctions dont les sens sont proches. Mais la programmation
objet repose aussi sur une notion de programmation incrémentale,
organisée autour de la représentation des données. Une sous-classe
contient au moins tous les champs de sa classe parente, et un certain
nombre de nouveaux champs. Une sous-classe peut aussi redéfinir
(spécialiser) certains champs de sa classe parente. La notation objet
pour l'invocation des méthodes utilise la notion d'héritage entre les
classes pour retrouver la fonction véritablement appelée, puisqu'on
applique toujours la fonction la plus spécifique dans la hiérarchie
des classes. La notation objet permet d'effectuer une liaison tardive
entre l'invocation d'une méthode et sa réalisation effective,
puisqu'on peut l'invoquer sans connaitre sa définition.
| 3.11 |
Droits d'accès, polymorphisme, surcharge et héritage |
|
La hiérarchie des classes intervient aussi dans les droits d'accès aux
champs des classes. Un quatrième type d'accès, l'accès protégé, permet
de restreindre l'accès aux seules sous-classes. Globalement, en Java,
il y a donc quatre types d'accès pour les membres d'une classe:
- public en préfixant un champ par public pour permettre
l'accès depuis toutes les classes,
- privé en préfixant un champ par private pour restreindre
l'accès aux seules expressions ou fonctions dans la classe courante,
- amical en ne mettant aucun préfixe devant la déclaration d'un
champ pour autoriser l'accès depuis toutes les classes du même
paquetage (c'est donc l'accès par défaut),
- protégé en préfixant un champ par protected pour permettre
l'accès aux seules expressions ou fonctions dans les sous-classes de
la classe courante.
Les méthodes redéfinies dans les sous-classes doivent avoir la même
signature (arguments et résultat) que celles des fonctions redéfinies.
Les méthodes redéfinies doivent également fournir au moins les mêmes
droits d'accès. Ainsi une méthode publique (par exemple toString
de la classe Object) ne peut être redéfinie en méthode privée
dans la classe Point.
Exercice 18
Donner un moyen de fournir un accès public aux objets d'une classe,
tout en contrôlant leurs créations, c'est-à-dire en interdisant les
accès directs aux constructeurs.
Le polymorphisme est la propriété de pouvoir appliquer la même
fonction a plusieurs types de données. Le code reste le même, seuls
les arguments et résultats peuvent changer. L'exemple typique est
celui de la fonction append sur les listes, qui concatène deux
listes. Le code est le même quel que soit le type de chacun des
éléments de liste. En Java, il n'y a pas de polymorphisme. Il est donc
impossible d'écrire append sans conversions explicites.
La surcharge est la propriété de donner un même nom à des fonctions
différentes (donc de code différent). Selon le type des arguments, on
appelera l'une de ces fonctions. En Java, la surcharge est partout
présente, par exemple pour avoir plusieurs constructeurs dans une même
classe. La surcharge est résolue statiquement, à la compilation du
programme.
L'héritage est la propriété de trouver dynamiquement la méthode
s'appliquant à un objet (par exemple pour toString). Cette
opération demande un temps constant quand il y a héritage simple. Le
mélange de la surcharge et de l'héritage peut arriver à des situations
compliquées.
Exercice 19
Dans l'exemple suivant, quelle est la valeur imprimée?
class C {
void f() { g(); }
void g() { System.out.println(1); }
}
class D extends C {
void g() { System.out.println(2); }
public static void main (String[ ] args) {
D o = new D();
o.f();
} } |
Un autre exemple est le suivant, où on a rajouté deux méthodes equals pour tester l'égalité des points et des points colorés.
class Point {
...
public boolean equals (Point p) {
return x == p.x && y == p.y;
}
}
class PointC extends Point {
...
public boolean equals (PointC p) {
return x == p.x && y == p.y && c == p.c;
}
static boolean f (Point p, Point q) {
return p.equals (q);
}
public static void main (String[ ] args) {
PointC p = new PointC (3, 4, JAUNE) ;
PointC q = new PointC (3, 4, ROUGE) ;
System.out.println(f(p, q));
}
} |
Le résultat est vrai. En effet, comme la surcharge de la
méthode equals est résolue statiquement dans le code de f,
on n'a comme seule information disponible sur q qu'il est un point
normal. On cherche donc une méthode equals prenant un argument
de type Point dans les sous-classes possibles pour
l'argument p de f (On sait qu'une telle méthode existera toujours
puisqu'il y a déjà cette méthode dans la classe Point de
p). Or, lors de l'appel de f dans main, alors p est un
point coloré. Dans la classe PointC de p, il n'existe pas de
méthode equals prenant un argument de type Point; on
appelle donc la méthode de sa surclasse Point. Le résultat est
donc vrai, puisque cette méthode ne teste pas l'argument
couleur. Certains peuvent trouver ce raisonnement logique; d'autres
peuvent s'inquiéter de son aspect peu intuitif.
En fait, si on veut que p.equals(q) spécialise simultanément
p et q pour appeler la méthode equals des points colorés
lorsque p et q sont deux points colorés, on doit résoudre le
problème non trivial dit des méthodes binaires. C'est impossible en
Java; dans d'autres langages, on y arrive en utilisant un argument de
type désignant l'objet lui-même. En Java, il n'y a pas de type
spécifique pour this. Cette notion fine de la programmation
étend le pouvoir expressif d'un langage de programmation (par exemple
c'est le cas en Ocaml). En Java, le problème disparait, mais la
puissance d'expression du langage est moins grande.
| 3.12 |
Classes abstraites et types disjonctifs |
|
Un classe abstraite de Java est une classe dont toutes les méthodes ne
sont pas définies. Pour celles-ci, on ne précise que leur
signature. Les classes abstraites s'appellent aussi classes virtuelles
dans d'autres langages de programmation.
Les types disjonctifs sont un cas d'utilisation des classes abstraites
dans la programmation par objets. Un type disjonctif est la somme
disjointe de plusieurs types. Prenons l'exemple des arbres de syntaxe
abstraite (ASA) pour les expressions arithmétiques, définis dans la
section 2.6 du chapitre précédent. Ces ASA peuvent être
définis récursivement (avec la notation BNF) comme l'ensemble T
suivant:
| T |
:= |
x | n | T + T | T-T | T × T
| T / T |
| x |
:= |
variable |
| n |
:= |
constante entière |
C'est la somme (disjointe) de 6 cas: constante, variable, addition,
soustraction, multiplication et division. Dans la classe Terme
correspondante (cf. le chapitre précédent), un champ nature
permettait de distinguer entre les 6 cas. En style orienté objets, on
peut définir 6 sous-classes d'une classe générique de la manière
suivante:
abstract class Terme {
abstract int eval (Environnement e);
abstract public String toString ();
}
class Var extends Terme {
String nom;
Var (String s) { nom = s; }
int eval (Environnement e) { return Environnement.assoc(nom, e); }
public String toString () { return nom; }
}
class Const extends Terme {
int valeur;
Const (int n) { valeur = n; }
int eval (Environnement e) { return valeur; }
public String toString () { return valeur + ""; }
}
class Add extends Terme {
Terme a1, a2;
Add (Terme x, Terme y) {a1 = x; a2 = y; }
int eval (Environnement e) { return a1.eval(e) + a2.eval(e); }
public String toString () { return "(" + a1 + " + " + a2 + ")"; }
}
class Soust extends Terme {
Terme a1, a2;
Soust (Terme x, Terme y) {a1 = x; a2 = y; }
int eval (Environnement e) { return a1.eval(e) - a2.eval(e); }
public String toString () { return "(" + a1 + " - " + a2 + ")"; }
}
class Mul extends Terme {
Terme a1, a2;
Mul (Terme x, Terme y) {a1 = x; a2 = y; }
int eval (Environnement e) { return a1.eval(e) * a2.eval(e); }
public String toString () { return "(" + a1 + " * " + a2 + ")"; }
}
class Div extends Terme {
Terme a1, a2;
Div (Terme x, Terme y) {a1 = x; a2 = y; }
int eval (Environnement e) { return a1.eval(e) / a2.eval(e); }
public String toString () { return "(" + a1 + " / " + a2 + ")"; }
}
class Test {
public static void main (String[ ] args) {
Terme t = ... ;
System.out.println (t);
Environnement e = ... ;
System.out.println (t.eval(e));
}
} |
où la classe Environnement est la classe de la
section 2.12.1 manipulant des listes d'association
entre les noms et valeurs des variables. La classe générique Terme est abstraite, car tous ses champs ne sont pas
définis. Comme les champs eval et toString sont
abstraits, chacune des 6 sous-classes (non abstraites) devra les
définir. Tout terme t aura donc deux méthodes toString et eval, pour l'imprimer et pour l'évaluer dans un environnement
donné.
Considérons l'expression (x+1)× (3 × y+1) et son arbre
de syntaxe abstraite t. Celui-ci est construit par:
Terme t = new Mul (
new Add (new Var ("x"), new Const (1)),
new Add(
new Mul (new Const (3), new Var ("y")),
new Const (1))); |
Alors t.eval(e) retourne la valeur 2002 dans l'environnement e
tel que x=90 et y=7. En fait l'évaluation commence par appliquer
la méthode eval de la classe Mul, qui est la plus petite
classe contenant t; celle-ci appelle la méthode eval sur son
premier argument, puis sur son deuxième argument et multiplie les deux
résultats. A nouveau l'appel d'eval sur le premier argument
engendre un appel de la méthode de la sous-classe Add puisque
c'est la plus petite contenant contenant t.a1, etc. C'est donc la
hiérarchie des classes qui contrôle les appels récursifs de la
fonction eval. Les cas de base de la récursion correspondent aux
sous-classes Var et Const, où on retourne la valeur
trouvée dans l'environnement ou la valeur stockée pour la constante
dans le champ valeur. A la différence de la fonction définie
dans le style procédural à la section 2.12.1, il
n'y a pas besoin d'un champ (nature) indiquant le sous-cas
dans la somme disjointe des types. Ici, on utilise les seuls champs
nécessaires dans chacun des sous-cas, plutôt que la réunion de tous
les champs comme dans la version procédurale.
Le cas de la méthode toString a été déjà vu dans l'exemple des
points colorés. Ici, chaque sous-classe définit sa fonction de
transformation en chaîne de caractères, en concaténant les résultats
obtenus récursivement pour les sous-termes. Il n'est pas besoin de
faire l'appel explicite à a1.toString ou a2.toString, car,
comme pour les fonctions d'impression, cet appel est généré
implicitement par l'opérateur de concaténation +.
L'exemple des ASA permet de bien comprendre la différence entre
programmation procédurale et programmation par objets. La version
orientée objet est complètement organisée autour du type des
données. Les fonctions d'évaluation et d'impression se retrouvent
dispersées dans les données. Si on veut, par exemple, rajouter
l'opération moins unaire qui calcule l'opposé de tout terme, il
suffira de rajouter une nouvelle classe avec ses propres méthodes sans
rien changer au reste, alors que, dans la version procédurale de la
section 2.12.1, il faudra faire de multiples
changements. Inversement, si on rajoute une nouvelle fonction, dans la
version orientée-objet, il faudra effectuer un changement dans chacune
des sous-classes, alors que ce changement ne se fera qu'à un seul
endroit dans la version procédurale. Choisir entre les deux styles de
programmation est souvent affaire de goût.
Il faut enfin mentionner que certains langages de programmation
existent avec des opérateurs explicites de somme disjointe sur
types. Ces opérateurs peuvent être plus ou moins sophistiqués, de
Pascal à ML. Mais il n'évitent pas le choix entre style procédural et
style par objets.
Exercice 20
Ecrire la méthode equals qui teste l'égalité (structurelle) de
deux termes.
Exercice 21
Calculer la dérivée d'un terme arithmétique en orienté-objet.
Exercice 22
Ecrire la méthode de belle-impression de termes arithmétiques en
orienté-objet.